
Figure 2.1: Kernel, thread, group image
Here's a simple explanation of how to use ComputeShader (hereafter "Compute Shader" if needed) in Unity. Compute shaders are used to parallelize simple operations using the GPU and perform large numbers of operations at high speed. It also delegates processing to the GPU, but it is different from the normal rendering pipeline. In CG, it is often used to express the movement of a large number of particles.
Some of the content that follows from this chapter uses compute shaders, and knowledge of compute shaders is required to read them.
Here, we use two simple samples to explain what will be the first step in learning a compute shader. These don't cover everything in compute shaders, so be sure to supplement the information as needed.
Although it is called ComputeShader in Unity, similar technologies include OpenCL, DirectCompute, and CUDA. The basic concepts are similar, especially with DirectCompute (DirectX). If you need more detailed information about the concept around the architecture, it is a good idea to collect information about these as well.
The sample in this chapter is "Simple Compute Shader" from https://github.com/IndieVisualLab/UnityGraphicsProgramming .
Figure 2.1: Kernel, thread, group image
Before explaining the concrete implementation, it is necessary to explain the concept of kernel (Kernel) , thread (Thread) , and group (Group) handled by the compute shader .
A kernel is a process performed on the GPU and is treated as a function in your code (corresponding to the kernel in general system terms).
A thread is a unit that runs the kernel. One thread runs one kernel. Compute shaders allow the kernel to run in parallel on multiple threads at the same time. Threads are specified in three dimensions (x, y, z).
For example, (4, 1, 1) will execute 4 * 1 * 1 = 4 threads at the same time. If (2, 2, 1), 2 * 2 * 1 = 4 threads will be executed at the same time. The same four threads run, but in some situations it may be more efficient to specify the threads in two dimensions, such as the latter. This will be explained later. For the time being, it is necessary to recognize that the number of threads is specified in three dimensions.
Finally, a group is a unit that executes a thread. Also, the threads that a group runs are called group threads . For example, suppose a group has (4, 1, 1) threads per unit. When there are two of these groups, each group has (4, 1, 1) threads.
Groups are specified in three dimensions, just like threads. For example, when a (2, 1, 1) group runs a kernel running on (4, 4, 1) threads, the number of groups is 2 * 1 * 1 = 2. Each of these two groups will have 4 * 4 * 1 = 16 threads. Therefore, the total number of threads is 2 * 16 = 32.
Sample (1) "SampleScene_Array" deals with how to execute an appropriate calculation with a compute shader and get the result as an array. The sample includes the following operations:
The execution result of sample (1) is as follows. Since it is only debug output, please check the operation while reading the source code.

Figure 2.2: Execution result of sample (1)
From here, I will explain using a sample as an example. It's very short, so it's a good idea to take a look at the compute shader implementation first. The basic configuration is a function definition, a function implementation, a buffer, and variables as needed.
SimpleComputeShader_Array.compute
#pragma kernel KernelFunction_A
#pragma kernel KernelFunction_B
RWStructuredBuffer<int> intBuffer;
float floatValue;
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * floatValue;
}
[numthreads(4, 1, 1)]
void KernelFunction_B(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] += 1;
}
Features include the numthreads attribute and SV_GroupID semantics, which will be discussed later.
As mentioned earlier, aside from the exact definition, the kernel refers to a single operation performed on the GPU and is treated as a single function in the code. Multiple kernels can be implemented in one compute shader.
In this example, KernelFunction_Athere is no kernel and the KernelFunction_Bfunction corresponds to the kernel. Also, the function #pragma kernelto be treated as a kernel is defined using. This distinguishes it from the kernel and other functions.
A unique index is given to the kernel to identify any one of the multiple defined kernels. The indexes are #pragma kernelgiven as 0, 1… from the top in the order defined by.
Create a buffer area to store the result of execution by the compute shader . The sample variable RWStructuredBuffer<int> intBuffer} corresponds to this.
If you want to give an arbitrary value from the script (CPU) side, prepare a variable in the same way as general CPU programming. In this example, the variable intValuecorresponds to this, and the value is passed from the script.
The numthreads attribute (Attribute) specifies the number of threads that execute the kernel (function). The number of threads is specified by (x, y, z). For example, (4, 1, 1), 4 * 1 * 1 = 4 threads execute the kernel. Besides, (2, 2, 1) runs the kernel in 2 * 2 * 1 = 4 threads. Both are executed in 4 threads, but the difference and proper use will be described later.
There are restrictions on the arguments that can be set in the kernel, and the degree of freedom is extremely low compared to general CPU programming.
The following the argument value セマンティクスis referred to as, in this example groupID : SV_GroupIDcity groupThreadID : SV_GroupThreadIDsets the. Semantics are meant to indicate what the value of the argument is and cannot be renamed to any other name.
The argument name (variable name) can be defined freely, but one of the semantics defined when using the compute shader must be set. In other words, it is not possible to implement an argument of any type and refer to it in the kernel, and the arguments that can be referenced in the kernel are selected from the specified limited ones.
SV_GroupIDIndicates in which group the thread running the kernel is running (x, y, z). SV_GroupThreadIDIndicates the number of threads in the group that runs the kernel with (x, y, z).
For example, in a group of (4, 4, 1), when running a thread of (2, 2, 1) SV_GroupID, returns a value of (0 ~ 3, 0 ~ 3, 0). SV_GroupThreadIDReturns a value of (0 ~ 1, 0 ~ 1, 0).
In addition to the semantics set in the sample, there are other SV_~semantics that start with and can be used, but I will omit the explanation here. I think it's better to read it after understanding the movement of the compute shader.
In the sample, the thread numbers are assigned to the prepared buffers in order. groupThreadIDIs given the thread number to run in a group. This kernel runs in (4, 1, 1) threads, so groupThreadIDis given (0 ~ 3, 0, 0).
SimpleComputeShader_Array.compute
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * intValue;
}
This sample runs this thread in groups (1, 1, 1) (from the script below). That is, it runs only one group, which contains 4 * 1 * 1 threads. As a result groupThreadID.xPlease make sure that the value of 0 to 3 is applied to.
* Although is groupIDnot used in this example, the number of groups specified in 3D is given as in the case of threads. Try substituting it and use it to see how the compute shader works.
Run the implemented compute shader from a script. The items required on the script side are as follows.
comuteShaderkernelIndex_KernelFunction_A, BintComputeBufferSimpleComputeShader_Array.cs
public ComputeShader computeShader;
int kernelIndex_KernelFunction_A;
int kernelIndex_KernelFunction_B;
ComputeBuffer intComputeBuffer;
void Start()
{
this.kernelIndex_KernelFunction_A
= this.computeShader.FindKernel("KernelFunction_A");
this.kernelIndex_KernelFunction_B
= this.computeShader.FindKernel("KernelFunction_B");
this.intComputeBuffer = new ComputeBuffer(4, sizeof(int));
this.computeShader.SetBuffer
(this.kernelIndex_KernelFunction_A,
"intBuffer", this.intComputeBuffer);
this.computeShader.SetInt("intValue", 1);
…
In order to run a kernel, you need index information to specify that kernel. The indexes are #pragma kernelgiven as 0, 1… from the top in the order defined by FindKernel, but it is better to use the function from the script side .
SimpleComputeShader_Array.cs
this.kernelIndex_KernelFunction_A
= this.computeShader.FindKernel("KernelFunction_A");
this.kernelIndex_KernelFunction_B
= this.computeShader.FindKernel("KernelFunction_B");
Prepare a buffer area to save the calculation result by the compute shader (GPU) on the CPU side. It is ComputeBufferdefined as in Unity .
SimpleComputeShader_Array.cs
this.intComputeBuffer = new ComputeBuffer(4, sizeof(int));
this.computeShader.SetBuffer
(this.kernelIndex_KernelFunction_A, "intBuffer", this.intComputeBuffer);
ComputeBufferInitialize by specifying (1) the size of the area to be saved and (2) the size of the data to be saved per unit. Spaces for four int sizes are provided here. This is because the execution result of the compute shader is saved as an int [4]. Resize as needed.
Then, implemented in the compute shader, (1) specify which kernel runs, (2) specify which buffer to use on which GPU, and (3) specify which buffer on the CPU corresponds to. To do.
In this example, the buffer area KernelFunction_A(2) referenced when (1) is executed is specified to correspond to intBuffer(3) intComputeBuffer.
SimpleComputeShader_Array.cs
this.computeShader.SetInt("intValue", 1);
Depending on what you want to process, you may want to pass a value from the script (CPU) side to the compute shader (GPU) side and refer to it. Most types of values ComputeShader.Set~can be set to variables in the compute shader using. At this time, the variable name of the argument set in the argument and the variable name defined in the compute shader must match. In this example, intValuewe are passing 1.
The kernel implemented (defined) in the compute shader is ComputeShader.Dispatchexecuted by the method. Runs the kernel with the specified index in the specified number of groups. The number of groups is specified by X * Y * Z. In this sample, 1 * 1 * 1 = 1 group.
SimpleComputeShader_Array.cs
this.computeShader.Dispatch
(this.kernelIndex_KernelFunction_A, 1, 1, 1);
int[] result = new int[4];
this.intComputeBuffer.GetData(result);
for (int i = 0; i < 4; i++)
{
Debug.Log(result[i]);
}
The execution result of the compute shader (kernel) is ComputeBuffer.GetDataobtained by.
Check the implementation on the compute shader side again. In this sample, the following kernels are running in 1 * 1 * 1 = 1 groups. The threads are 4 * 1 * 1 = 4 threads. It also intValuegives 1 from the script.
SimpleComputeShader_Array.compute
[numthreads(4, 1, 1)]
void KernelFunction_A(uint3 groupID : SV_GroupID,
uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] = groupThreadID.x * intValue;
}
groupThreadID(SV_GroupThreadID)Will contain a value that indicates which thread in the group the kernel is currently running on, so in this example (0 ~ 3, 0, 0) will be entered. Therefore, groupThreadID.xis 0 to 3. In other words, intBuffer[0] = 0 ~ intBuffer[3] = 3will be until are executed in parallel.
When running different kernels implemented in one compute shader, specify the index of another kernel. In this example, KernelFunction_Arun after KernelFunction_B. Furthermore KernelFunction_A, the buffer area used in is KernelFunction_Balso used.
SimpleComputeShader_Array.cs
this.computeShader.SetBuffer
(this.kernelIndex_KernelFunction_B, "intBuffer", this.intComputeBuffer);
this.computeShader.Dispatch(this.kernelIndex_KernelFunction_B, 1, 1, 1);
this.intComputeBuffer.GetData(result);
for (int i = 0; i < 4; i++)
{
Debug.Log(result[i]);
}
KernelFunction_BExecutes code similar to the following. This time intBufferis KernelFunction_APlease note that specifies continue what we used in.
SimpleComputeShader_Array.compute
RWStructuredBuffer<int> intBuffer;
[numthreads(4, 1, 1)]
void KernelFunction_B
(uint3 groupID : SV_GroupID, uint3 groupThreadID : SV_GroupThreadID)
{
intBuffer[groupThreadID.x] += 1;
}
In this sample, KernelFunction_Aby intBuffera 20-3 it has been given in the order. Therefore, KernelFunction_Bafter running, make sure the value is between 1 and 4.
ComputeBuffers that are no longer in use must be explicitly destroyed.
SimpleComputeShader_Array.cs
this.intComputeBuffer.Release();
The intent of specifying multidimensional threads or groups is not covered in this sample. For example, (4, 1, 1) thread and (2, 2, 1) thread both run 4 threads, but it makes sense to use the two properly. This will be explained in the sample (2) that follows.
Sample (2) In "SampleScene_Texture", the calculation result of the compute shader is acquired as a texture. The sample includes the following operations:
The execution result of sample (2) is as follows. Generates a texture that has a horizontal and vertical gradient.
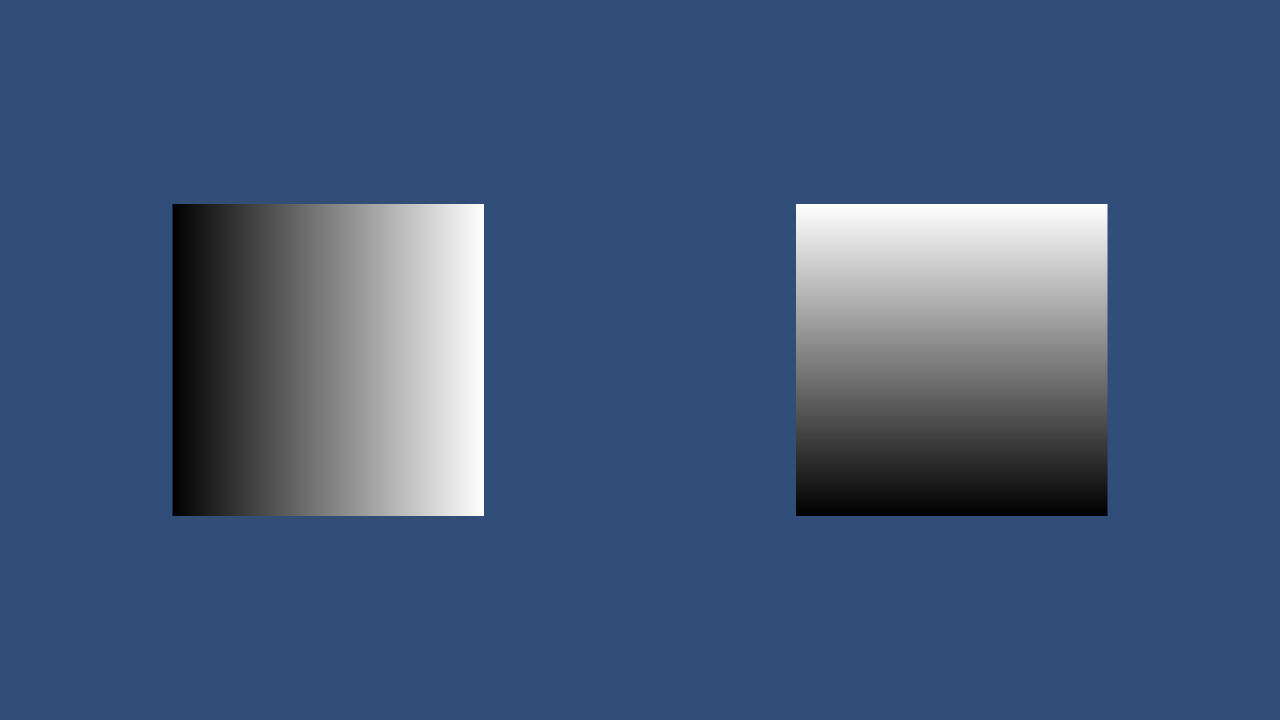
Figure 2.3: Execution result of sample (2)
See the sample for the overall implementation. In this sample, the following code is roughly executed in the compute shader. Notice that the kernel runs in multidimensional threads. Since it is (8, 8, 1), it will be executed in 8 * 8 * 1 = 64 threads per group. Another RWTexture2D<float4>major change is that the calculation result is saved in.
SimpleComputeShader_Texture.compute
RWTexture2D<float4> textureBuffer;
[numthreads(8, 8, 1)]
void KernelFunction_A(uint3 dispatchThreadID : SV_DispatchThreadID)
{
float width, height;
textureBuffer.GetDimensions(width, height);
textureBuffer[dispatchThreadID.xy]
= float4(dispatchThreadID.x / width,
dispatchThreadID.x / width,
dispatchThreadID.x / width,
1);
}
SV_DispatchThradIDNo semantics were used in sample (1) . It's a bit complicated, but it shows "where the thread running a kernel is in all threads (x, y, z)" .
SV_DispathThreadIDIs the SV_Group_ID * numthreads + SV_GroupThreadIDvalue calculated by. SV_Group_IDIndicates a group with (x, y, z), and indicates the SV_GroupThreadIDthreads contained in a group with (x, y, z).
For example, suppose you run a kernel in a (2, 2, 1) group that runs on (4, 1, 1) threads. One of the kernels runs on the (2, 0, 0) th thread in the (0, 1, 0) th group. In this case SV_DispatchThreadID, (0, 1, 0) * (4, 1, 1) + (2, 0, 0) = (0, 1, 0) + (2, 0, 0) = (2, 1, 0) ).
Now let's consider the maximum value. In the (2, 2, 1) group, when the kernel runs on the (4, 1, 1) thread, the (3, 0, 0) th thread in the (1, 1, 0) th group Is the last thread. In this case SV_DispatchThreadID, (1, 1, 0) * (4, 1, 1) + (3, 0, 0) = (4, 1, 0) + (3, 0, 0) = (7, 1, 0) ).
After that, it is difficult to explain in chronological order, so please check while reading the entire sample.
Sample (2) dispatchThreadID.xysets groups and threads to show all the pixels on the texture. Since it is the script side that sets the group, we need to look across the script and the compute shader.
SimpleComputeShader_Texture.compute
textureBuffer[dispatchThreadID.xy]
= float4(dispatchThreadID.x / width,
dispatchThreadID.x / width,
dispatchThreadID.x / width,
1);
In this sample, we have prepared a texture of 512x512, but when dispatchThreadID.xis 0 ~ 511, it dispatchThreadID / widthis 0 ~ 0.998…. In other words, as dispatchThreadID.xythe value (= pixel coordinates) increases, it will be filled from black to white.
Textures consist of RGBA channels, each set from 0 to 1. When all 0s, it is completely black, and when all 1s, it is completely white.
The following is an explanation of the implementation on the script side. In sample (1), we prepared an array buffer to store the calculation results of the compute shader. In sample (2), we will prepare a texture instead.
SimpleComputeShader_Texture.cs
RenderTexture renderTexture_A;
…
void Start()
{
this.renderTexture_A = new RenderTexture
(512, 512, 0, RenderTextureFormat.ARGB32);
this.renderTexture_A.enableRandomWrite = true;
this.renderTexture_A.Create();
…
Initialize RenderTexture by specifying the resolution and format. Note RenderTexture.enableRandomWritethat this is enabled to enable writing to the texture.
Just as you can get the index of the kernel, you can also get how many threads the kernel can run (thread size).
SimpleComputeShader_Texture.cs
void Start()
{
…
uint threadSizeX, threadSizeY, threadSizeZ;
this.computeShader.GetKernelThreadGroupSizes
(this.kernelIndex_KernelFunction_A,
out threadSizeX, out threadSizeY, out threadSizeZ);
…
DispathExecute the process with the method. At this time, pay attention to how to specify the number of groups. In this example, the number of groups is calculated by "horizontal (vertical) resolution of texture / number of threads in horizontal (vertical) direction".
When thinking about the horizontal direction, the texture resolution is 512 and the number of threads is 8, so the number of horizontal groups is 512/8 = 64. Similarly, the vertical direction is 64. Therefore, the total number of groups is 64 * 64 = 4096.
SimpleComputeShader_Texture.cs
void Update()
{
this.computeShader.Dispatch
(this.kernelIndex_KernelFunction_A,
this.renderTexture_A.width / this.kernelThreadSize_KernelFunction_A.x,
this.renderTexture_A.height / this.kernelThreadSize_KernelFunction_A.y,
this.kernelThreadSize_KernelFunction_A.z);
plane_A.GetComponent<Renderer>()
.material.mainTexture = this.renderTexture_A;
In other words, each group will process 8 * 8 * 1 = 64 (= number of threads) pixels. Since there are 4096 groups, we will process 4096 * 64 = 262,144 pixels. The image is 512 * 512 = 262,144 pixels, which means that we were able to process just all the pixels in parallel.
The other kernel fills using the y coordinate instead of x. At this time, note that a value close to 0, a black color, appears at the bottom. You may need to consider the origin when working with textures.
Multidimensional threads and groups work well when you need multidimensional results, or when you need multidimensional operations, as in sample (2). If sample (2) is to be processed in a one-dimensional thread, the vertical pixel coordinates will need to be calculated arbitrarily.
You can confirm it when you actually implement it, but when you have a stride in image processing, for example, a 512x512 image, the 513th pixel is the (0, 1) coordinate, and so on. ..
It is better to reduce the number of operations, and the complexity increases as the advanced processing is performed. When designing processing with compute shaders, it's a good idea to consider whether you can take advantage of multidimensionality.
In this chapter, we have provided introductory information in the form of explaining samples of compute shaders, but from now on, we will supplement some information necessary for learning.
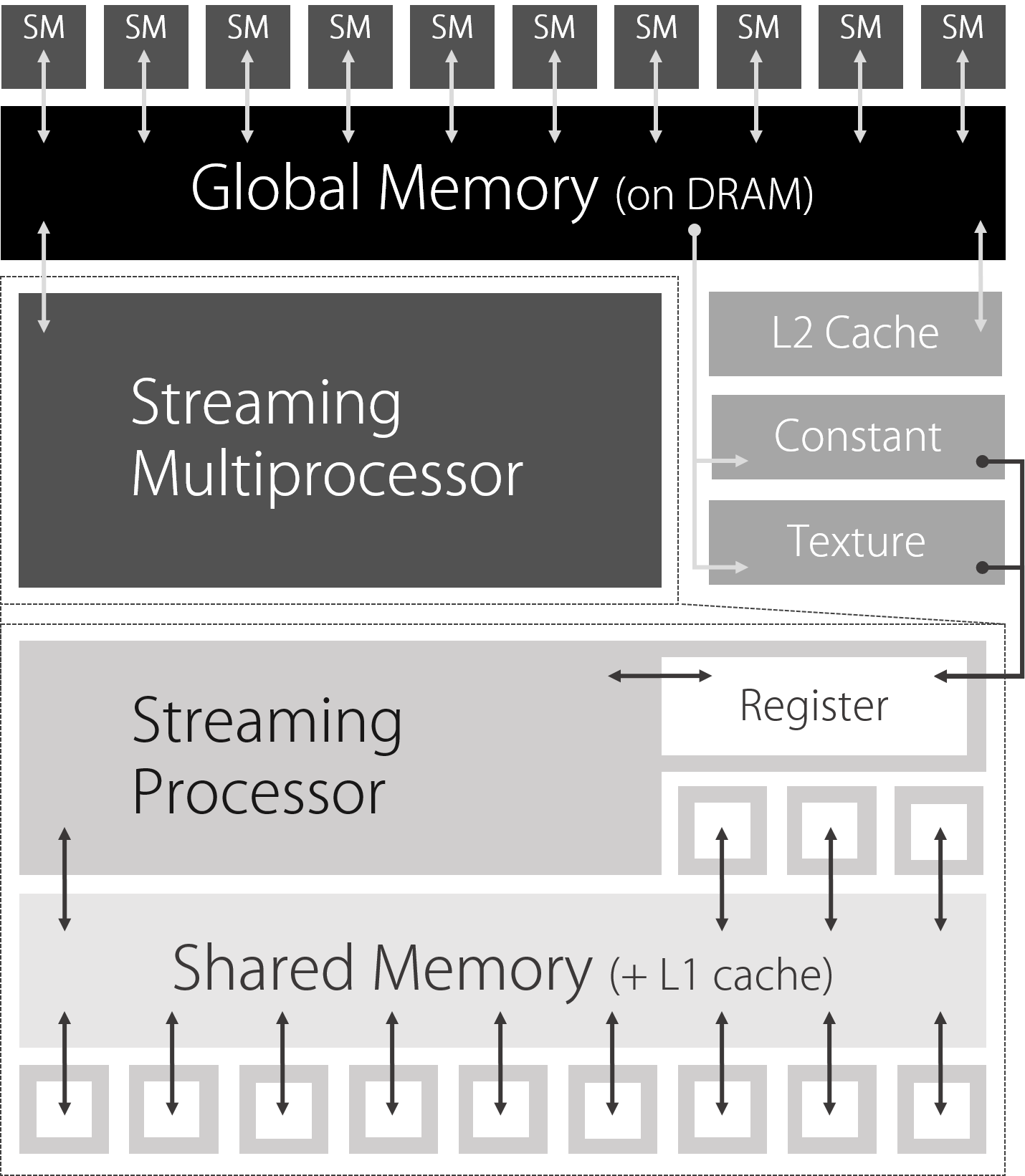
Figure 2.4: Image of GPU architecture
If you have a basic knowledge of GPU architecture and structure, it will be useful for optimizing it when implementing processing using compute shaders, so I will introduce it here a little.
The GPU is equipped with a large number of Streaming Multiprocessors (SM) , which are shared and parallelized to execute the given processing.
The SM has multiple smaller Streaming Processors (SPs) , and the SP calculates the processing assigned to the SM.
The SM has registers and shared memory, which allows it to read and write faster than global memory (memory on DRAM) . Registers are used for local variables that are referenced only within the function, and shared memory can be referenced and written by all SPs that belong to the same SM.
In other words, it is ideal to know the maximum size and scope of each memory and realize an optimal implementation that can read and write memory at high speed without waste.
For example, shared memory, which you may need to consider most, is groupshareddefined using storage-class modifiers . Since this is an introduction, I will omit a concrete introduction example, but please remember it as a technique and terminology necessary for optimization and use it for future learning.
The fastest accessible memory area located closest to the SP. It consists of 4 bytes and contains kernel (function) scope variables. Since each thread is independent, it cannot be shared.
A memory area located in the SM, which is managed together with the L1 cache. It can be shared by SPs (= threads) in the same SM and can be accessed fast enough.
A memory area on the DRAM, not on the GPU. References are slow because they are far from the processor on the GPU. On the other hand, it has a large capacity and can read and write data from all threads.
The memory area on the DRAM, not the GPU, stores data that does not fit in the registers. References are slow because they are far from the processor on the GPU.
This memory is dedicated to texture data and handles global memory exclusively for textures.
It is a read-only memory and is used to store kernel (function) arguments and constants. It has its own cache and can be referenced faster than global memory.
If the total number of threads is larger than the number of data you actually want to process, it will result in threads that are executed (or not processed) meaninglessly, which is inefficient. Design the total number of threads to match the number of data you want to process as much as possible.
Introducing the upper limit of the current specifications at the time of writing. Please note that it may not be the latest version. However, it is required to implement it while considering these restrictions.
The limits on the number of threads and groups were not mentioned in the discussion. This is because it changes depending on the shader model (version). It is expected that the number that can be paralleled will continue to increase in the future.
The group limit is (x, y, z), 65535 each.
The upper limit of shared memory is 16 KB per unit group, and the size of shared memory that a thread can write is limited to 256 bytes per unit.
Other references in this chapter are: